Daniel Hernandez писал 20.06.2012 20:03:
that
ruby code is converted to a bytecode sintactical tree that is
interpreted by YARV. This is different to compile C, because the
output of GCC is a machine code and not a sintactical tree.
Bytecode has nothing to do with syntactical trees. Abstract syntax tree
is a notation used to represent the source code, e.g.
irb> require ‘ripper’; require ‘pp’
irb> pp Ripper.sexp(“puts 1 + 2”)
[:program,
[[:command,
[:@ident, “puts”, [1, 0]],
[:args_add_block,
[[:binary, [:@int, “1”, [1, 5]], :+, [:@int, “2”, [1, 9]]]],
false]]]]
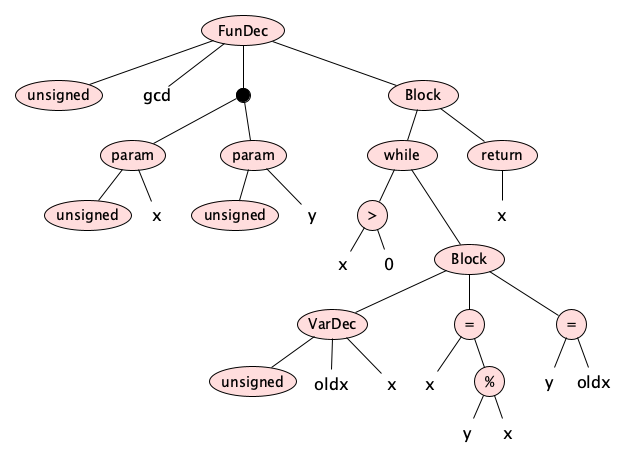
The mentioned structure can be thought of as a tree because it does not
have any loops (if you can’t imagine it, try to find inspiration in
this
image: http://cs.lmu.edu/~ray/images/gcdast1.png)
Bytecode is a format used akin to machine code, but for a virtual
machine
specialized for a certain language. Nothing (except maybe common sense)
prevents you from creating a very real, silicon processor for the YARV
bytecode; it isn’t inherently inferior to x86 machine code. Bytecode
looks like this:
puts RubyVM::InstructionSequence.new(“puts 1 + 2”).disasm
== disasm:
<RubyVM::InstructionSequence:@>==========
0000 trace 1 (
-
0002 putself
0003 putobject 1
0005 putobject 2
0007 opt_plus ic:2
0009 send :puts, 1, nil, 8, ic:1
0015 leave
As you can see, it’s very similar to assembler code, but of a kind
developed specially for Ruby.
Ruby 1.8 walks each node of the AST and interprets them. This is very
slow.
Ruby 1.9 first converts the AST to the bytecode and then executes the
bytecode.
This still isn’t very fast, but at least it is much faster than walking
the AST.
{kind=link}
{kind=link}