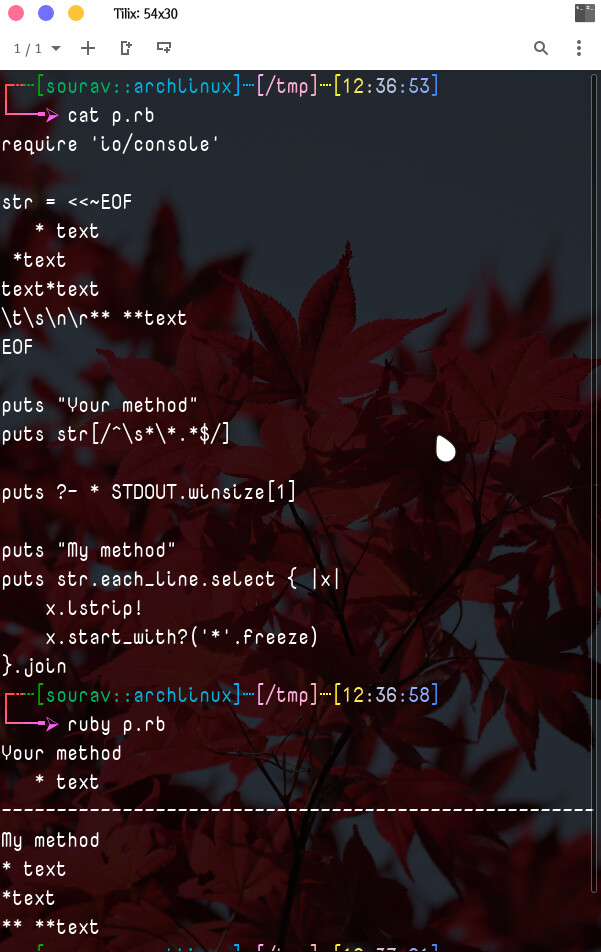
I am writing a regular expression for Ruby. I want it to match all lines that begin with a *, skipping optional white space. The following regular expression does this correctly on rubular.com:
/^\s*\*.*$/
For example, in the following text, this regular expression correctly matches the first two lines, and correctly does not match the third line:
* text
*text
text*text
But when I use this regular expression in Ruby, none of these three lines match. If I remove the ^, which indicates start of line, Ruby and rubular.com give the same result: they match the first two lines fully, and match the third line starting at the *. But that is not what I am trying to do. My current solution uses /\s*\*.*$/ (or, equivalently, /\*.*$/), both of which unfortunately also match text*text.
Is there a reason why Ruby is not matching the behavior I see on rubular? I would like to find a way to get the regex expression listed at the top of this post to work in Ruby the same way it does on rubular.
I am a complete newcomer to Ruby, so any tips or suggestions are much appreciated!